למידה חישובית 2025
- 135 שאלות
- 5 תגובות
- 0% הושלמו
- equalizer סטטיסטיקות
- share שתף







מנהלים:

Discuss, Learn and be Happy דיון בשאלות
help
brightness_4
brightness_7
format_textdirection_r_to_l
format_textdirection_l_to_r
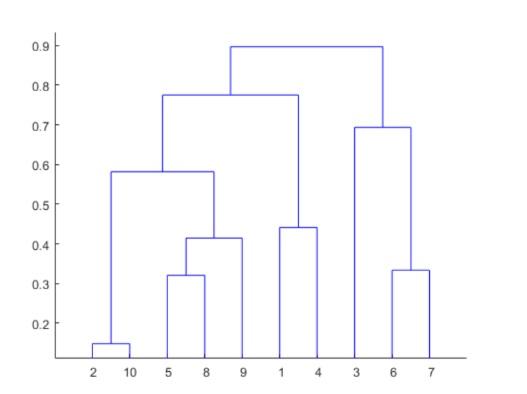
ביצעתם קלאסטרינג היררכי, וקיבלתם את ה Dendrogram הבא: אם תבצעו חלוקה על פי חתך בגובה 0.5 , כמה צברים תקבלו? (מועד א 2022)
1
| done | ||
מיין לפי
מרחק המינג (Hamming) בין שתי מחרוזות בעלות אורך זהה, הוא מספר המקומות שבהם סימנים מקבילים בשתי המחרוזות שונים זה מזה Hamming function can be used as a loss function (מועד א 2022)
1
| done | ||
מיין לפי
זמן הלימוד הנדרש להפעלת הפרוצדורה LOOCV Leave one out cross validation על מדגם עם 100 דוגמאות, ארוך לפחות פי 10 מזמן הלימוד הפרוצדורה 10-folds CV על אותו מדגם (מועד א 2022)
1
| done | ||
מיין לפי
באלגוריתם Adaboost גודל הEnsemble שנבנה שווה תמיד למספר האיטרציות שנקבע על ידי המשתמש (מועד א 2022)
1
| sentiment_very_satisfied |
מיין לפי
לצורך שלב חילוץ מאפיינים חדשים בגישת Deep learning הממומש באמצעות רשת נוירונים, אין צורך לקבל נתונים מסווגים (labeled) , אלא ניתן להסתפק רק בנתונים שהם unlabeled (מועד א 2022)
1
| done | ||
מיין לפי
ברשת נוירונים מסוג auto encoder מספר הנוירונים בשכבת הקלט ומספר הנוירונים בשכבת הפלט זהה (מועד א 2022)
1
| done | ||
מיין לפי
למידה היא שיפור בעקבות ניסיון של משימה מסויימת. דוגמא טובה ל"משימה" היא: (מועד א 2022)
1
| done | ||
| done |
מיין לפי
True or false: GRU is more efficient than RNN for long sequences, and it has 3 gates (מועד א 2022)
1
מיין לפי
איזה מהבאים נכון: על פי עקרון ERM - Empirical risk minimization (מועד א 2023)
1
| done | ||
מיין לפי