למידה חישובית 2025
- 135 שאלות
- 5 תגובות
- 0% הושלמו
- equalizer סטטיסטיקות
- share שתף







מנהלים:

Discuss, Learn and be Happy דיון בשאלות
help
brightness_4
brightness_7
format_textdirection_r_to_l
format_textdirection_l_to_r
עצי החלטה מבצעים מטבעם feature selection ע"י בחירת התכונות האינפורמטיביות ביותר לפיצול בכל צומת (מועד א 2024)
1
| done | ||
מיין לפי
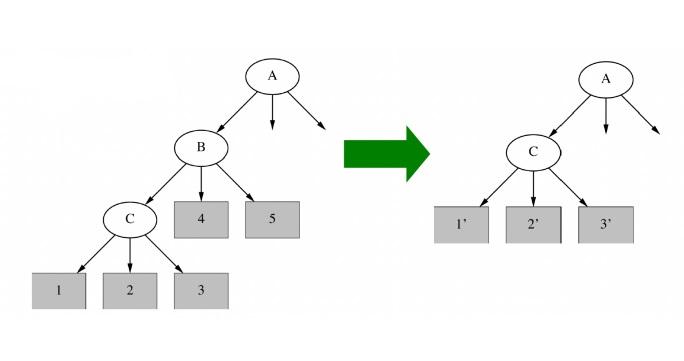
איזה סוג של pruning מתאים לנתונים שבציור? (מועד ב 2024)
1
מיין לפי
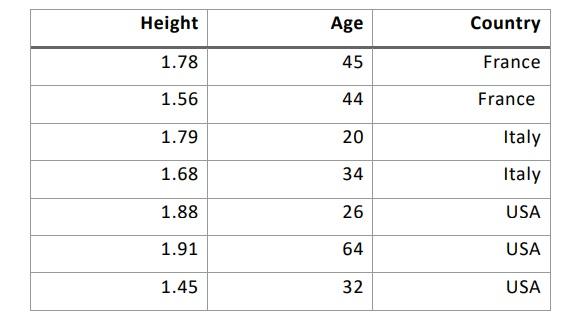
מה הוא מדד הפיצול ה -לא- מתאים לעץ החלטה בהנתן 3 תכונות שמתוארות בציור? (מועד ב 2024)
1
| done | ||
מיין לפי
Even if the learning rate is very large, every iteration of gradient descent will improve the loss (מועד ב 2022)
1
| done |
מיין לפי
In a given deep learning architecture, if we increase the batch size, should we increase or decrease the learning rate? (מועד ב 2022)
1
| done |
We should increase the learning rate because, in the bigger batch of the GD step, we have less noise.
מיין לפי
A binary classification model that for every sample returns the common class in the training set is an example of a lazy learner (מועד ב 2022)
1
| done |
A lazy learner only performs during prediction, whereas here it needs to compute the common label at training time
מיין לפי
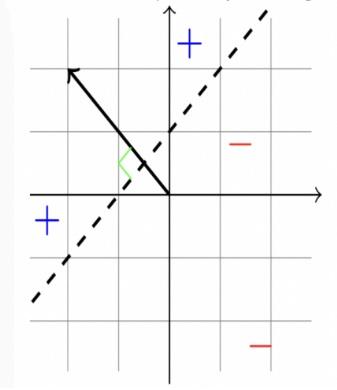
A 2D linear classifier is represented by the next diagram What represents the weights vector of the linear classifier (w)? (מועד ב 2022)
1
| done | ||
מיין לפי
Momentum helps SGD navigate the relevant directions and softens the oscillations in the irrelevant directions. (מועד ב 2022)
1
| done | ||
מיין לפי
In Least Absolute Shrinkage and Selection Operator (LASSO) regression compare to standard linear regression, there is an additional parameter that needs to be updated during gradient descent iteration (מועד ב 2022)
1
| done |
מיין לפי